Comment manipuler des données numériques stockées sur de l’ADN ?
Biologie
Chimie
Ingénierie
Numérique
|
L’ADN offre une solution pour stocker durablement un très grand nombre de données numériques. Cependant, une fois encodées, il reste pour l’instant difficile de retrouver une information précise ou de la manipuler. Des chercheurs du CNRS, de l’Université de Tokyo et de l’ESPCI Paris-PSL ont mis en application pour la première fois une nouvelle méthode utilisant des enzymes, pour offrir une première piste afin de surmonter cet obstacle. Leurs travaux sont publiés dans Nature le 20 octobre 2022.
La nature a sans doute inventé la meilleure des solutions pour stocker un très grand nombre de données : l’ADN. De ce constat est née l’idée d’utiliser ce support pour y contenir les informations numériques. Pour cela, il s’agit de transformer une donnée numérique binaire (0 ou 1), en lettre correspondant aux quatre briques de l’ADN (ATCG).
Cependant, comment retrouver un type de donnée précis dans toutes les informations que l’ADN contient ? Comment calculer directement, à partir des données sous forme ADN, sans avoir à repasser par des données électroniques ? Ce sont les défis auxquels souhaitent répondre les équipes du laboratoire de recherches international Limms (CNRS/Université de Tokyo) et du laboratoire Gulliver (CNRS/ESPCI Paris-PSL). Les scientifiques ont expérimenté une nouvelle approche utilisant des enzymes, et s’inspirant du fonctionnement des neurones et des réseaux de neurones artificiels pour effectuer des calculs complexes directement sur des données stockées sur de l’ADN.
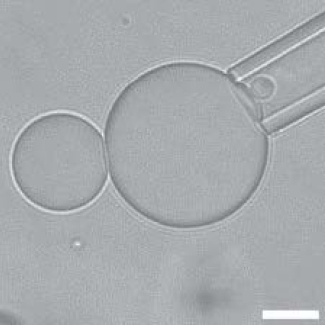
L’une des performances de leurs travaux est de parvenir à arranger les réactions chimiques de trois enzymes pour reproduire la manière dont les neurones traitent l’information en réseaux. Ce faisant, les scientifiques ont ainsi formé des « neurones chimiques » artificiels aptes à simuler la capacité de ces cellules à faire des calculs complexes. Ces « neurones chimiques » s’avèrent alors capables de réaliser des calculs directement sur des brins d’ADN, et les résultats de ces calculs sont ensuite communiqués au monde extérieur grâce à des signaux fluorescents.
Pour la toute première fois, les scientifiques sont parvenus à superposer deux couches de ces neurones artificiels, pour affiner les calculs. Ils se sont également appuyés sur la microfluidique, pour miniaturiser les réactions et réaliser des dizaines de milliers d’expériences, et ainsi préciser les résultats.
Ce travail est l’aboutissement de 10 ans de collaboration entre des scientifiques français spécialistes de biochimie, et des chercheurs japonais spécialistes d’ingénierie microfluidique. A terme, ces nouveaux travaux pourraient permettre d’améliorer les tests de dépistage de certaines maladies, mais également de manipuler de gigantesques bases de données contenues dans de l’ADN.
S’il est préservé de l’eau, de l’air et de la lumière, l’ADN peut se conserver durant des centaines de milliers d’années sans aucun apport d’énergie. Contenus dans une capsule de quelques centimètres, il peut contenir jusqu’à 500 téraoctets de données numériques. Alors que l’humanité devrait produire 175 zettaoctets1 de données en 2025, la solution du stockage ADN semble être une alternative face à la quantité d’informations attendues pour des supports actuels fragiles, énergivores et volumineux : stockée sur de l’ADN, l’intégralité des données mondiales actuelles pourrait tenir dans le volume d’une boîte à chaussures. Faciliter le stockage ADN sera le but du PEPR MoleculArxiv, un programme de recherche prioritaire lancée par le CNRS en mai dernier.
- 1Soit 1,75x1023 octets
Bibliographie
Nonlinear decision-making with enzymatic neural networks. S. Okumura, G. Gines, N. Lobato-Dauzier, A. Baccouche, R. Deteix, T. Fujii, Y. Rondelez & A. J. Genot. Nature, 20 octobre 2022. DOI : https://doi.org/10.1038/s41586-022-05218-7